
I came across this open source tool while I was looking for different ways to test Lambda Functions. In the words of Alex Casalboni (who created the tool):
AWS Lambda Power Tuning is a state machine powered by AWS Step Functions that helps you optimize your Lambda functions for cost and/or performance in a data-driven way.
It works by invoking a given Lambda function multiple times with different memory allocations, ranging from 128 MB to 10 GB. The resulting execution logs are then analysed to determine which configuration offers the best trade-off between speed and cost-effectiveness.
AWS Lambda Power Tuning allows for parallel execution as well as cross-region invocations. It can be run on any Lambda Function, regardless of the language it is written in, and you only need to provide a Lambda function’s ARN for it to start testing.
I had two Lambda functions that I’d written recently for a reminders app - one that added a reminder to a DynamoDB table, and one that retrieved reminders. When I wrote them, I just left them both at the default 128MB memory allocation since they won’t be invoked often so I thought I’d test them using this tool.
There are five options available to deploy the tool:
- AWS Serverless Application Repository (SAR)
- Using the AWS SAM CLI
- Using the AWS CDK
- Using Terraform by Hashicorp and SAR
- Using native Terraform
I’ll cover how to deploy the tool using the AWS SAM CLI, but if you’d like to use another option you can see instructions for the other deployment options here
Installing using the AWS SAM CLI has the following prerequisites:
- Install the AWS CLI and configure your credentials
- Install the AWS SAM CLI
- Install Docker
Once you have everything you need, go ahead and clone the repository:
git clone https://github.com/alexcasalboni/aws-lambda-power-tuning.git
Next, you’ll need to build the Lambda layer and any other dependencies:
cd ./aws-lambda-power-tuning
sam build -u
Once the build succeeds, deploy the application using the guided SAM deploy mode:
sam deploy -g
The deployment will guide you - choose a unique name for the stack and choose the region you want to deploy into, then you can accept the default values for everything else. When the deployment has completed, you’re ready to specify some execution parameters and execute the script to run the state machine.
The script that you need to run is scripts/execute.sh, but before you do that there is a config file that can be filled out to specify execution parameters - scripts/sample-execution-input.json. All of the available options are shown below.
Parameter | Description |
|---|---|
| lambdaARN (required) type: string | Unique identifier of the Lambda function you want to optimize. |
| num (required) type: integer | The # of invocations for each power configuration (minimum 5, recommended: between 10 and 100). |
| powerValues type: string or list of integers | The list of power values to be tested; if not provided, the default values configured at deploy-time are used; you can provide any power values between 128MB and 10,240MB. ⚠️ New AWS accounts have reduced concurrency and memory quotas (3008MB max). |
| payload type: string, object, or list | The static payload that will be used for every invocation (object or string); when using a list, a weighted payload is expected in the shape of [{"payload": {...}, "weight": X }, {"payload": {...}, "weight": Y }, {"payload": {...}, "weight": Z }], where the weights X, Y, and Z are treated as relative weights (not percentages); more details in the Weighted Payloads section. |
| payloadS3 type: string | An Amazon S3 object reference for large payloads (>256KB), formatted as s3://bucket/key; it requires read-only IAM permissions, see payloadS3Bucket and payloadS3Key below and find more details in the S3 payloads section. |
| parallelInvocation type: boolean default: false | If true, all the invocations will run in parallel. ⚠️ Note: depending on the value of num, you might experience throttling. |
| strategy type: string default: "cost" | It can be "cost" or "speed" or "balanced"; if you use "cost" the state machine will suggest the cheapest option (disregarding its performance), while if you use "speed" the state machine will suggest the fastest option (disregarding its cost). When using "balanced" the state machine will choose a compromise between "cost" and "speed" according to the parameter "balancedWeight". |
| balancedWeight type: number default: 0.5 | Parameter that represents the trade-off between cost and speed. Value is between 0 and 1, where 0.0 is equivalent to "speed" strategy, 1.0 is equivalent to "cost" strategy. |
| autoOptimize type: boolean default: false | If true, the state machine will apply the optimal configuration at the end of its execution. |
| autoOptimizeAlias type: string | If provided - and only if autoOptimize is true, the state machine will create or update this alias with the new optimal power value. |
| dryRun type: boolean default: false | If true, the state machine will invoke the input function only once and disable every functionality related to logs analysis, auto-tuning, and visualization; this is intended for testing purposes, for example to verify that IAM permissions are set up correctly. |
| preProcessorARN type: string | The ARN of a Lambda function that will be invoked before every invocation of lambdaARN; more details in the Pre/Post-processing functions section. |
| postProcessorARN type: string | The ARN of a Lambda function that will be invoked after every invocation of lambdaARN; more details in the Pre/Post-processing functions section. |
| discardTopBottom type: number default: 0.2 | By default, the state machine will discard the top/bottom 20% of “outlier invocations” (the fastest and slowest) to filter out the effects of cold starts and remove any bias from overall averages. You can customize this parameter by providing a value between 0 and 0.4, where 0 means no results are discarded and 0.4 means 40% of the top/bottom results are discarded (i.e. only 20% of the results are considered). |
| sleepBetweenRunsMs type: integer | If provided, the time in milliseconds that the tuner will sleep/wait after invoking your function, but before carrying out the Post-Processing step, should that be provided. This could be used if you have aggressive downstream rate limits you need to respect. By default this will be set to 0 and the function won’t sleep between invocations. This has no effect if running the invocations in parallel. |
| disablePayloadLogs type: boolean default: false | If true, suppresses payload from error messages and logs. If preProcessorARN is provided, this also suppresses the output payload of the pre-processor. |
| includeOutputResults type: boolean default: false | If true, the average cost and average duration for every power value configuration will be included in the state machine output. |
| onlyColdStarts type: boolean default: false | If true, the tool will force all invocations to be cold starts. The initialization phase will be considerably slower as num versions/aliases need to be created for each power value. |
When testing my Lambda Functions, I opted for very basic parameters including the option to run each invocation as a cold start since they’re not executed that often:
{
"lambdaARN": "arn:aws:lambda:eu-west-2:1234567890:function:get-reminder",
"powerValues": [128, 256, 512, 1024],
"num": 50,
"payload": {},
"onlyColdStarts": true
}
The state machine returns the following output once completed:
{
"results": {
"power": "128",
"cost": 0.0000002083,
"duration": 2.9066666666666667,
"stateMachine": {
"executionCost": 0.00045,
"lambdaCost": 0.0005252,
"visualization": "https://lambda-power-tuning.show/#<encoded_data>"
},
"stats": [{ "averagePrice": 0.0000002083, "averageDuration": 2.9066666666666667, "value": 128}, ... ]
}
}
Included in the output is a data visualisation tool that provides information at a glance. Here are the two visualisations from the Lambda Functions that I tested:
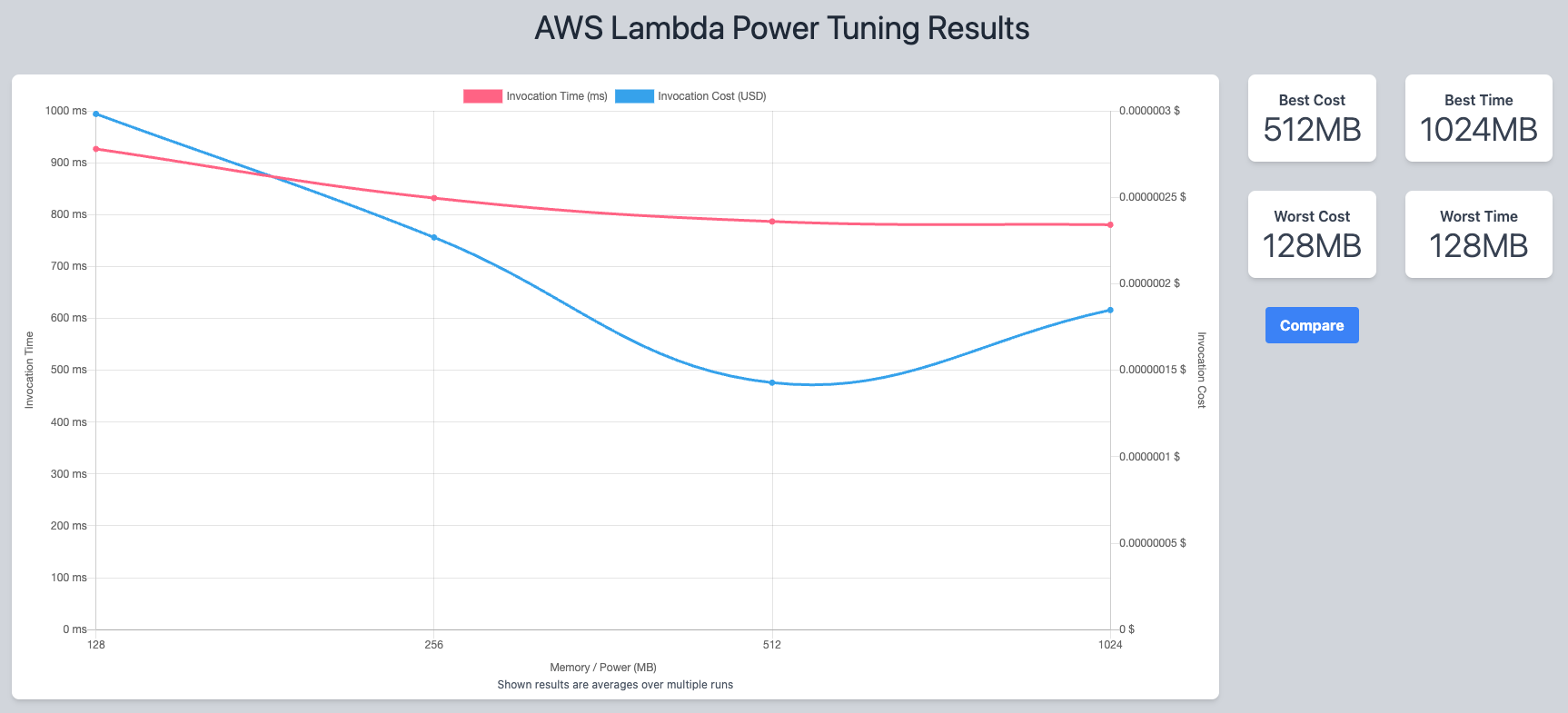
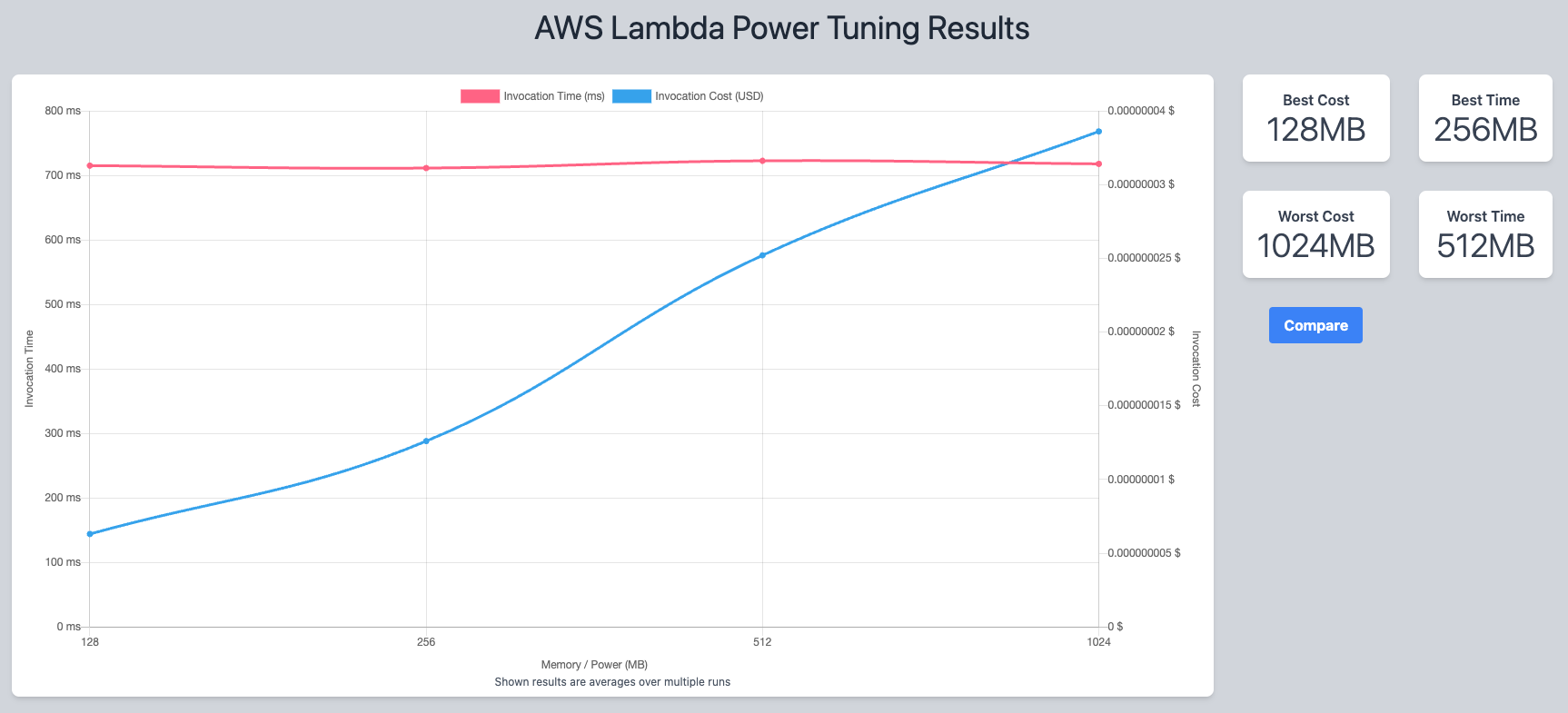
As you can see from the first example, it would be beneficial in terms of both time and cost for me to increase the memory on that function from 128MB to 512MB. If you look at the second example however, you can see that I’m best off keeping that particular Lambda Function’s memory where it is.
This is an incredibly useful tool, and definitely one that I’ll use in the future. It left me wondering if you could use it in a deployment pipeline to have functions automatically optimised - maybe the subject of another post!
{kind=link}